
Development of my dissertation to pursue the PhD degree in Information and Communication Technologies at the University of Granada, Spain.
Information Retrieval for the
<\WoT> Web of Things
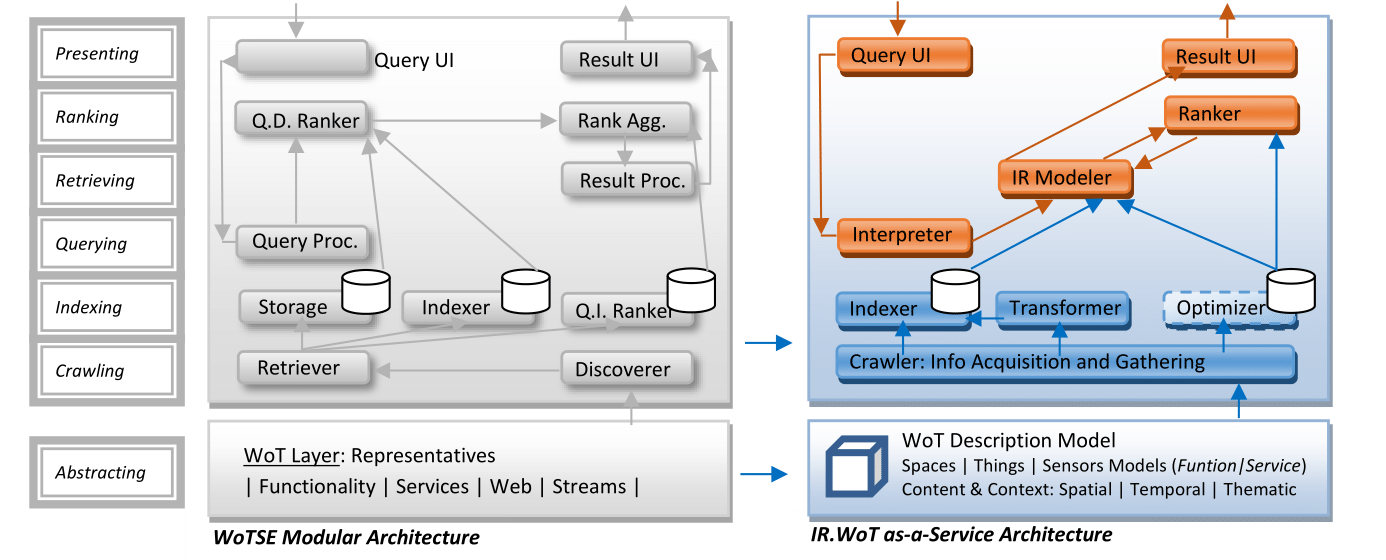
Our approach, named IR.WoT is an Information Retrieval system for the Web of Things. In the figure, we map the IR.WoT components to the IR data flow in the modular architecture of [Tran et al, 2017], https://doi.org/10.1145/3092695. Where a generic Web of Things Search Engine (WoTSE) has been referenced as a comparison framework to guide future IR developments. We have cross-correlated our IR.WoT as a service architecture with the modular counterpart. The former provides a functional cloud-based resource perspective and the latter provides a data flow-oriented analysis. In the following sections, we describe each functional modular part of IR.WoT and we present an overview of internal cloud architecture.
The NEXI (Narrowed Extended XPath I) query language developed by the INEX community (Trotman & Sigurbjörnsson, Narrowed Extended XPath I (NEXI), 2005), (Trotman & Sigurbj_rnsson, NEXI, now and next, 2004) it is based on XPath expressions to access and navigate within the components and elements of the IR Test XML-based document collection. Because exact containment of elements may be less critical in IR applications, NEXI only supports descendant or auto ("//") notation for routes. To specify classified recovery, NEXI replaces the contains function with about.
In the framework of the IR.WoT, user-facing fields and restrictions are captured through the Query UI Module, which are then translated from natural language to NEXI language queries. Conventionally, translation can be done using various methods given the structure and content of the XML documents in the collection in order to build information retrieval type queries for XML. For the proposed model, the following types of NEXI queries are available:
Our Dynamic Index proposal is to analyse the combination of three data structures with the application of three combined XML dynamic strategies. Data structures: the dictionary that makes up the inverted index can be stored in a hash table or a similar structure, and the list of publications for each term t can be stored in a fixed-length array structure or a similar structure too.
Strategies for Dynamic XML Indexing maintenance:
Development of my dissertation to pursue the PhD degree in Information and Communication Technologies at the University of Granada, Spain.
You can contact us at Department of Computer Science and AI of the University of Granada: